Snapshot: Case Study # 1
Looking to enhance its claims capabilities, a leading auto insurance company decided to adopt Big Data analytics to streamline its subrogation process. Although subrogation is unarguably regarded as the quickest path to payback, it is also one of the most complex elements in the claims value chain, since it requires human judgment and is a high touch-point process.
Using Big Data analytics, the company was able to successfully identify and consolidate the data points used to find subrogation opportunities. It also developed a comprehensive analytics model to complement the technology, replacing its previous judgment-heavy, labor-intensive methodologies.
The new solution enabled the insurer to increase its subrogation recovery by $1 million within the first month of implementation. Six months down the line the total increment rose to $12 million.
Snapshot: Case Study # 2
In the aftermath of a big hurricane, a leading home insurer found itself swamped with thousands of claims per day. As if the sheer volume wasn’t enough, claimants were using all possible channels to connect with the insurer, including social networks, phone calls, fax, SMS, blogs and tweets, which only made matters worse.
The insurer set up a new Big Data-powered infrastructure to acknowledge receipt of loss notifications to all the claimants, and posted all incoming communications inside a central repository. An automated triaging solution was also implemented to comb through the large volume of claims and find out types of evidences which conveyed significant damage and/or emotional stress of the reporter.
This enabled the insurer to prioritize claims and assign them to the appropriate handlers correctly which, in turn, helped boost the company’s brand value and sales.
We’ve all no doubt come across the term ‘insurance claims fraud,’ but few of us have likely delved deep into it to understand its ramifications. Beyond its innocuous surface, it is a globally growing crime and is ripping apart the entire eco-system around insurers. It is not only causing enormous losses to insurers, but also more far-reaching consequences, including bankruptcy, high premiums, job losses and people losing their savings. In short, the consequences are catastrophic.
According to the estimates calculated by the Coalition Against Insurance Fraud (CAIF), organized insurance schemes steal at least $80 billion per year in the United States alone. To make matters worse, individuals and organized rings view insurance fraud as a low-risk, high-reward game because of the shelter that the insurance industry and its regulatory/compliance mandates provides them. That is why in spite of dedicated efforts by insurers, fraud loss is involved in around 10 percent of claims payout made each year, according to the National Insurance Crime Bureau.
Over a period of time insurers have taken up a variety of initiatives to combat fraud. Apart from training their employees, running customer educations program and liaising with regulatory bodies, most insurers also have a dedicated Special Investigation Unit (SIU) team which uses sophisticated software to identify the probability of fraud.
The Claims Fulfillment engine used by SIU teams has been integrated with various tools and processes to reduce chances of fraud. But crime seems to evolve faster than regulations and monitoring mechanisms, and fraudsters are always one step ahead in inventing new techniques. The traditional methodologies used by an insurer cannot automatically evolve to capture new trends and patterns and thus, when it comes to exploratory analysis, it is always one step behind.
Over the past few years, the velocity, variety and volume of data coming into organizations has increased dramatically. For example, First Notice of Loss (FNOL), which had conventionally been a telephone call process, is now capturing data through multiple avenues like email, fax, SMS and image attachments. Then, throughout the lifecycle of a claim, the handler can still continue to receive hundreds of reports and communications from all interested parties. More often than not, these come in various forms and the sheer size and variety make it very difficult for conventional techniques to find inconsistencies.
To take a simple example, say someone is claiming “Cause of Loss – Fire” in a homeowner’s claim. But then one of the loss investigation reports reveals that the person’s spouse has two more claims in the past year and that the vendor assessment reports have photographs which suggest that no expensive items were present in the house at the time of fire breakout. Meanwhile, the claimant has tweeted that he has gifted his grandfather clock to his brother. Thus, clues are present in a plethora of sources that the house was intentionally torched but the conventional rules would fail to link them together to derive a conclusion because of existing heterogeneous sources and timing of arrivals.
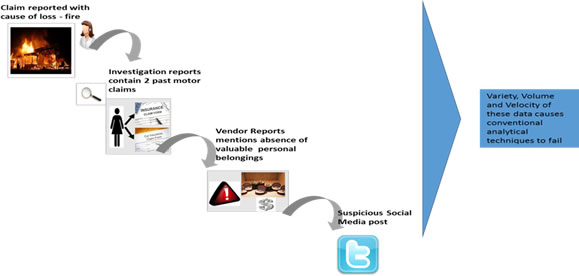
Fig 1 – Disparate sources of data poses problem to conventional techniques
To address these challenges, insurers have started to use Big Data technologies to handle the huge volume and variety of data that they get flooded with throughout the lifecycle of an insurance policy.
Big Data processing takes into account Transaction, Interaction as well as Observational data. In a typical Big Data architecture all of these data types are arranged in forms of structured, semi-structured, as well as unstructured formats through advanced data transformation techniques.
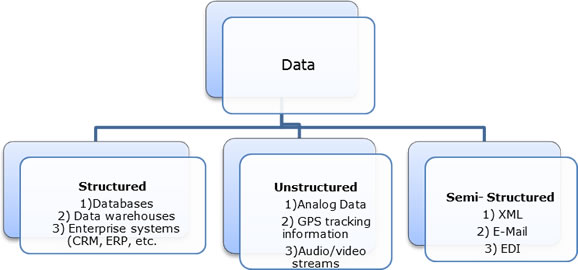
Fig 2 – Data organization in Big Data world
The only problem with this type of data storage and manipulation is that it requires huge investments in data infrastructure and buy-in from very senior stakeholders in the insurance organization.
However, the advantage that new methodologies provide over traditional solutions is that the system can evolve over a period of time to detect new dependencies. Thus, throughout the claims management lifecycle insurers can keep receiving live data feeds, such as blogs, tweets and social media posts and scrutinize them along with their sentiments to ascertain the veracity of the claim on an ongoing basis.
In a Big Data-driven world, handlers will no longer be limited to a static fraud score; rather, they will get a moving fraud score over the lifecycle of the claim which will be more realistic, and in turn, will drive individual elements within claims fulfillment (e.g. subrogation, salvage and repair coordination) accordingly. They’ll also have a much bigger data set to compare against which will give them more accurate forecasts when conducting trend analysis from historical data.
Today, there are advanced claims tools available in the market which can take feed from Big Data analytics and assign a claim. These technologies take into account handler-expertise available, trait of the claim, along with automated escalation mechanisms.
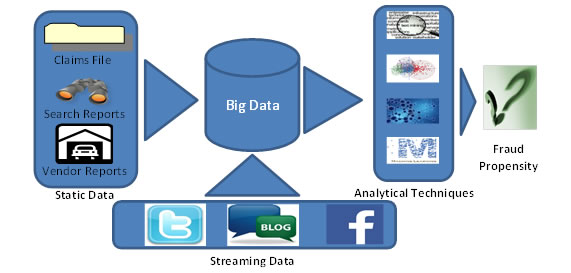 Fig 3 – Integration between Big Data & predictive analytics provides better scope in capturing frauds
Fig 3 – Integration between Big Data & predictive analytics provides better scope in capturing frauds
There have already been many success stories that have come out of Big Data analytics. Various products like Hadoop, Lexis Nexis HPCC, Teradata AsterData, Kognito and Microsoft Dryad are available in the market and all of them have been quite successful in providing valuable insights in various industries. In this era of technical explosion where all of us are getting flooded with a deluge of data, now is the time for P&C insurers to embrace Big Data-driven analytics to fight claims fraud more effectively.
By Mohan Babu, associate vice president and head of the insurance practice at Infosys and Soumya Chattopadhyay, lead consultant – insurance practice at Infosys.
Was this article valuable?
Here are more articles you may enjoy.
 Berkshire Utility Presses Wildfire Appeal With Billions at Stake
Berkshire Utility Presses Wildfire Appeal With Billions at Stake  UBS Top Executives to Appear at Senate Hearing on Credit Suisse Nazi Accounts
UBS Top Executives to Appear at Senate Hearing on Credit Suisse Nazi Accounts  China Bans Hidden Car Door Handles in World-First Safety Policy
China Bans Hidden Car Door Handles in World-First Safety Policy  Charges Dropped Against ‘Poster Boy’ Contractor Accused of Insurance Fraud
Charges Dropped Against ‘Poster Boy’ Contractor Accused of Insurance Fraud 
Want to stay up to date?
Get the latest insurance news
sent straight to your inbox.