Loss runs are insurance carrier reports that show how many claims have been filed under business insurance policies. Insurance carrier underwriters and brokers require loss runs for every business they insure, and use the prior claims history to help price premiums, analyze and reduce risks, and identify weaknesses.
Personal lines insurance carriers for personal auto and property claims have the benefit of use of the Comprehensive Loss Underwriting Exchange (CLUE), a contributory claims database used to review claims history. Unfortunately, no such central repository exists for commercial claims.
As a result, the process of getting claims history from insurance carriers, creating the loss summaries, and analyzing the loss data is an extremely cumbersome and manual process that drains significant amount of effort and time.
With over 5 million business establishments with more than 20 employees (US Census Bureau – 2017 County Business Patterns), requiring commercial insurance coverage, there are millions of loss runs in circulation annually.
Carriers provide loss runs in unstructured PDF and Excel formats specific to carrier templates with no industry standards. Given that an average business customer has multiple insurance policies across multiple carriers – obtaining a consistent claims view for any one business is a tedious challenge given that the brokers need to manually convert the unstructured data into one comprehensive structured format they can analyze.
Brokers typically procure loss runs 90 days prior to the policy renewal. This is most important milestone for controlling insurance costs and retaining clients by helping them keep losses low. Having visibility into this critical information will reduce vulnerabilities and positively impact the bottom line for customers, agents, and carriers.
The manual nature of procuring and analyzing loss runs for any one business makes this process time consuming, expensive, and inefficient. On average, each business has 2.3 insurance policies (auto, property, general liability, workers’ compensation, and more) with brokers receiving the loss runs at least twice a year. Given that there are millions of businesses in the United States, a very large number of loss runs are in circulation with millions of hours and billions of dollars spent annually by the industry.
Carriers Aren’t Motivated to Invest in Simplifying the Problem
Loss runs are an essential component for obtaining quotes for new business and insurance carriers must comply with the regulatory requirement of providing loss runs to brokers and the insured clients. However, if carriers simplify and consolidate the process of procuring loss runs, brokers will more easily obtain better quotes from competing carriers. Keeping the status quo means brokers are more likely to stay with one carrier out of simplicity, rather than shopping around.
Challenges in Solving the Problem
Commercial insurance carriers have their own loss run formats that establish how and what is shared regarding claims history. No consistent terminology exists on how to report policy type, lines of business, or claim categories, making it extremely complex to analyze loss runs in a normalized format across carriers. For example, few carriers provide loss description without a cause of loss detail, leaving brokers to determine the cause of loss by manually reviewing loss descriptions of hundreds of claims in a loss run report.
Extracting data from unstructured documents such as PDFs is an emerging area but training algorithms to extract the extremely complex loss run templates from different carriers is an extremely difficult task.
The challenge is made even more complicated in that it also requires significant knowledge specific to the insurance industry, such as policy types, types of claims, what is included & excluded in claim payments, carrier formats, etc. This domain knowledge is scarce in the technology world.
Evolution of InsureTech and Cognitive AI
The first wave of InsurTech focused on digital distribution of insurance products and many new InsurTech’s are evolving that are purpose built for solving more complex core insurance problems. The insurance industry is full of unstructured data in policies, loss runs, quotes and submissions and emails. According to our estimates the insurance industry is unable to use the 80 percent of the data in these unstructured documents that are stored in their file repositories.
Advances in cloud computing and machine learning is showing significant promise to tackle the seemingly limitless unstructured data that exists today.
Extraction and ingestion of unstructured data is a growing space, especially in property and casualty (P&C) insurance use cases such as streamlining submissions and intake, claim analysis from loss runs, and policy checking to identify coverage gaps.
The Solution to the Loss Run Problem
Any solution to the loss run challenge needs to address the 4 areas identified below.
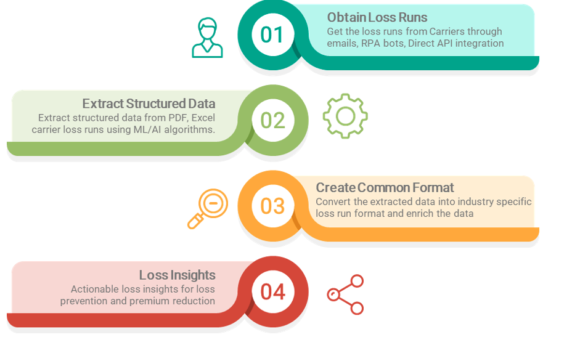
- Obtaining loss runs from carriers
As part of digital initiatives, carriers are working to create more application programing interface (API) integrations between carriers, brokers, and customers. The industry would benefit tremendously if carriers could share the structured loss information through API. Brokers are using Robotic Process Automation (RPA) bots to access carrier websites and download the loss runs. Structured data exchange through API is the best way forward but take times to establish wholesale adoption and it is still in its infant stages. Fortunately, with more emerging carrier and broker digital initiatives the hope is that the process will accelerate quickly.
- Extracting the data from the loss runs
As carrier loss runs are delivered in PDF or Excel formats, InsurTech’s that are working on loss runs need to demonstrate that they can extract data accurately and also at a level of granularity for each claim. For any InsurTech to succeed in this space, they need to target achieving 99% accuracy levels. The industry simply will not accept algorithms that only produce 60 percent to 70 percent accuracy.
In the United States alone, there are over 2,000 property and casualty insurance carriers, with each carrier creating its own proprietary loss run templates. However, the top 100 P&C carrier loss runs cover 70 percent to 80 percent of the commercial market. InsurTech’s that have trained the top 100 carrier loss run templates with acceptable accuracy levels stand to gain significant market share.
- Standardizing the data into a carrier agnostic common format
The next challenge is rationalizing different carrier formats into a common industry dataset. Different carriers have different ways of sharing claim details — policy types, claim types, payment types, and what is included or excluded in payments varies from carrier to carrier. Hence the solution needs to provide a comprehensive industry dataset that can be created from any carrier loss run.
- Creating actionable insights from loss history
To provide the most value, the solution should provide actional insights into claim history, allowing brokers and customers to prevent losses and analyze trends.
Any solution that can address these four areas will have significant impact and will drive tremendous value to the insurance industry.
Opportunities and Benefits
If successfully solved, this can open many new opportunities. For example, brokers will have customer claims history across multiples lines, independent of carrier, to analyze and advise their clients on risk control and prevention. Furthermore, carriers receive many loss runs as part of new business submissions, but are unable to leverage this data due to their inability to extract data from unstructured documents efficiently. However, with available InsurTech solutions that can accurately extract unstructured data, carriers can create a huge repository of historic claim data that allows for more loss analysis, risk control, loss prevention, and automating the process of experience rating calculations.
Brokers, carriers, risk control, and actuarials can all significantly benefit from this new pool of data that is otherwise currently unavailable without significant manual effort.
The ability to analyze loss runs accurately and timely will eliminate common blind spots and give a complete view of clients’ losses, allowing better business decisions. This will help reduce vulnerability to risk and improve organizations’ bottom line.
Summary and Conclusion
Analysis of commercial loss runs is one of the big pain points in the insurance industry, complicated by nonstandard, unstructured loss runs (PDF, Excel) from carriers. Until recently there has been no solution to this problem and the industry has accepted the manual review and laborious review process. Thanks to cloud computing and advancements in machine learning, computer vision, and artificial intelligence technologies, InsurTechs are making tremendous progress in solving the problem of unstructured data including loss runs. The end to end solution that can address the problem of getting the loss runs from carriers, extracting the data, converting to a common format, and delivering actionable insights will significantly add value to the industry by saving effort, time, reducing losses, and eliminating coverage gaps.
Most of the InsurTech’s focus on digital distribution, but as the InsurTech industry expands, new players are emerging to solve the complex and deep industry problems such as loss runs.
It is only a matter of time before the industry sees a leader emerge that can solve the complex problem of loss runs in commercial lines.
Was this article valuable?
Here are more articles you may enjoy.
 Elon Musk Alone Can’t Explain Tesla’s Owner Exodus
Elon Musk Alone Can’t Explain Tesla’s Owner Exodus  Portugal Rolls Out $2.9 Billion Aid as Deadly Flooding Spreads
Portugal Rolls Out $2.9 Billion Aid as Deadly Flooding Spreads  One out of 10 Cars Sold in Europe Is Now Made by a Chinese Brand
One out of 10 Cars Sold in Europe Is Now Made by a Chinese Brand  Why 2026 Is The Tipping Point for The Evolving Role of AI in Law and Claims
Why 2026 Is The Tipping Point for The Evolving Role of AI in Law and Claims 
Want to stay up to date?
Get the latest insurance news
sent straight to your inbox.